Une solution R pour industrialiser les backtestings
Avant le déploiement du projet, la majorité des traitements étaient réalisés en utilisant des programmes MATLAB (3), avec les contraintes que cela implique. La philosophie de MATLAB dans l’usage qui en était fait chez SFIL se prêtant peu à l’automatisation, de nombreuses tâches d’ajustement de paramètres étaient en effet réalisées « manuellement », lors de chaque backtesting.
Au-delà du coût des opérations, notamment de prétraitement des données, leur non-automatisation était par ailleurs source d’erreurs potentielles et obligeait à de très nombreux contrôles qui, dans une logique industrielle, peuvent être évités. D’un point de vue compétence enfin, l’expertise MATLAB est de plus en plus difficile à trouver, notamment sur des problématiques de type Data Science. Les nouveaux modes de production de backtestings devaient permettre de lever cette contrainte opérationnelle.
Après l’analyse d’une première chaîne représentative, deux grands principes ont été édictés pour mener à bien l’industrialisation des backtestings :
- conserver les moteurs de calcul sous MATLAB afin de garantir la continuité de production entre les modèles existant et le backtestings. Ces codes étant également audités.
- migrer les autres phases au profit d’une solution permettant une meilleure industrialisation : extraction des données ; prétraitements, ces étapes ayant été clairement identifiées comme prioritaires du fait d’un code complexe et de nombreux contrôles manuels ; génération de rapports.
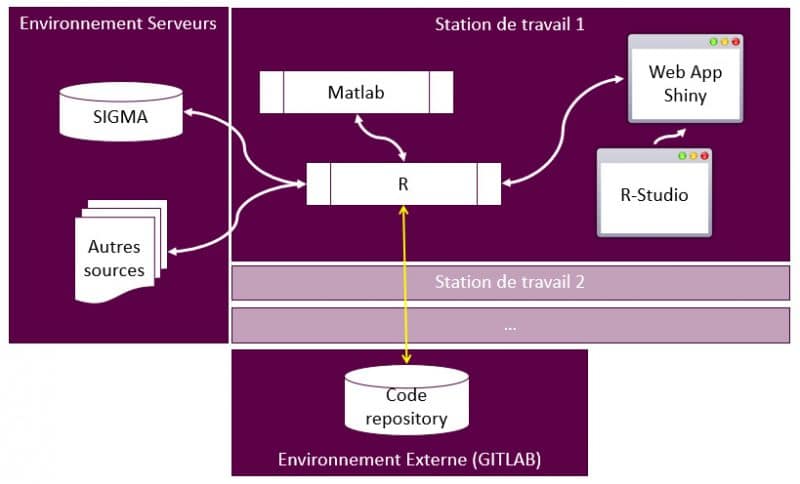
Les équipes de SFIL avaient déjà réalisé des développements avec R. Le langage de programmation et son logiciel libre associé ont donc naturellement été choisis. L’architecture cible pour industrialiser l’ensemble du processus a ensuite été définie selon le schéma ci-dessous, avec une suite de packages R indépendants et complémentaires. L’appel au cœur des calculs des backtestings, écrits en MATLAB, se fait directement depuis R, sans que l’utilisateur ait besoin d’interagir avec MATLAB.
Schéma 2 : Architecture cible du processus
Le transfert des compétences au centre du projet
Le développement de packages R et l’utilisation d’un gestionnaire de code ont constitué le principal défi technique de ce projet. Pour les équipes de SFIL, il y avait là une vraie opportunité pour monter en compétence en se formant à ces nouvelles techniques et méthodes. Pour rendre les équipes de SFIL complètement autonomes, le projet a été organisé de la façon suivante :
- migration d’une première chaîne représentative, définition de l’architecture cible, et initialisation des packages R par les équipes de Datastorm ;
- formation et accompagnement continus des équipes de SFIL, amenées à migrer les autres backtestings.
Point d’orgue de cette collaboration, une application web shiny a été développée pour permettre aux analystes de réaliser et de paramétrer aisément les différentes étapes nécessaires à la réalisation des backtestings… et cela, sans avoir à coder :
- indicateurs de disponibilités des données et lancement des procédures SQL permettant d’extraire les tables sources ;
- contrôle qualité et statistiques descriptives ;
- paramétrisation et lancement des backtestings.
Pour la Direction des risques de SFIL, l’industrialisation des backtestings aura relevé d’une initiative à forte valeur ajoutée pour trois raisons :
- tout d’abord une réduction significative du risque opérationnel grâce à l’uniformisation de l’exécution d’un backtesting dans toutes ses dimensions (constitution des données ; tests et analyses statistiques ; rapport).
- Ensuite une démocratisation du profil du réalisateur : il n’est plus nécessaire d’être spécialiste du code pour réaliser un backtesting, ce qui apporte de la souplesse dans le staffing. L’accent a été mis sur l’uniformisation des sources de données ainsi que la normalisation du processus afin d’aboutir à un outil simple, ne nécessitant pas de connaissances techniques, et donc accessible à tous.
- Enfin, une meilleure efficacité opérationnelle avec la réduction des coûts en ETP et en délais de réalisation. L’industrialisation va permettre aux équipes de se consacrer davantage aux travaux de modélisation, une telle amélioration concoure à mieux équilibrer le rapport Charge/Ressources.
Merci à :
Idriss Alassane M Salla, Responsable de la Modélisation Quantitative, SFIL
Julien Chambert, Analyste Quantitatif, Modélisation Quantitative SFIL
Ismael Maiga Salifou, Analyste Quantitatif, Modélisation Quantitative SFIL
Benoît Thieurmel, Directeur des opérations, Datastorm
Lyès Boucherai et Martin Masson, Data Scientists, Datastorm
(3) – Système interactif de calcul numérique et de visualisation graphique