Avec plus de 3500 boutiques, 30 millions de clientes à travers le monde, Yves Rocher est un géant de la cosmétique dont la stratégie marketing se décline autour d’une valeur mère : une relation client de proximité. Pour réduire le nombre de mailings papiers sans perdre sa performance commerciale, l’entreprise bretonne a fait appel à Datastorm. Objectif : explorer de nouvelles méthodes de scoring basées sur des techniques de machine learning.
N°1 de la cosmétique en France, Yves Rocher a su depuis des décennies instauré une relation de proximité avec ses clientes, notamment entretenue par des campagnes de mailing papier. Pour son marché français (700 boutiques, 8 millions de clientes), Yves Rocher génère ainsi une quinzaine de campagnes par an. Une stratégie marketing qui s’avère redoutablement efficaces : une majorité de clientes qui se présentent en boutique sont munies de ces courriers.
15 campagnes de mailing, 5 groupes de clientes constitués selon une segmentation RFM (habitudes d’achat) : Yves Rocher produit chaque année 75 scores dont l’entreprise a souhaité revoir la méthodologie avec deux objectifs :
- Explorer des méthodes de machine learning permettant d’augmenter la performance des scores et ainsi réduire le nombre de mailings papiers sans perdre l’efficacité commerciale de ce canal.
- Porter la méthodologie retenue sur Google Cloud Platform en lieu et place de la solution historique développée en SAS.
Etape 1 : refonte du score
CREATION DE NOUVEAUX AGREGATS
La méthodologie actuelle d’Yves Rocher repose sur la production de scores par régression logistique pour chacun des 5 segments de clientes et un regroupement saisonnier de campagne. Nous avons pour notre part travaillé sur les données agrégées de 2 segments correspondant à des clientes venant rarement en magasin.
Première étape : créer des agrégats plus riches à partir des données détaillées des transactions des clientes pour identifier des comportements d’achat plus fins.
Pour l’ensemble des nouveaux agrégats, plusieurs vues ont été calculées : annuelle, semestrielle et trimestrielle par rapport au mois de la campagne considérée, avec des évolutions annuelles, semestrielles et trimestrielles.
LE MACHINE LEARNING AU CHEVET DU SCORING
L’objectif étant de mettre en évidence le potentiel des algorithmes de machine learning sur la performance des campagnes, nous avons retenu les algorithmes de type « arbres de partitionnement », notamment connus pour apporter de bons résultats sur des problématiques similaires de scoring : random forests, gradient boosting et xgboost.
Ces différentes méthodes de machine learning ont été évaluées selon deux critères :
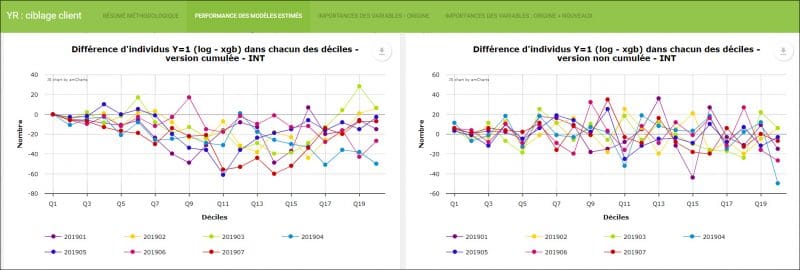
AUC : pour l’optimisation des hyperparamètres d’une même méthode. Les différences d’AUC entre les nouveaux modèles testés par rapport au modèle logistique initial étaient relativement faibles, de l’ordre du centième. Il paraissait cependant intéressant de regarder comment se répartissait la variable réponse par rapport aux valeurs du score.
Nombre de clientes retournées en magasin : (dont la variable réponse, Y, vaut 1) par tranche et selon les différents taux de ciblage des mailings (70, 80 ou 90 % de la population). En comparant une nouvelle méthode par rapport à la régression logistique, on la jugera meilleure si pour un pourcentage x de la population ciblée, i.e les x % des scores les plus élevés, on capte plus de clientes retournées en magasin (i.e Y=1). On regarde dans notre cas la performance pour des taux de ciblages allant de 70 à 90 % de la population, l’entreprise ayant l’habitude de cibler la quasi-totalité des 2 segments considérés.