Auteurs : Titouan Robert, Thomas Zamojski
Introduction
Au-delà des problèmes classiques rencontrés dans l’industrialisation d’une chaîne de traitement de données, une application de Machine Learning (ML) apporte un défi supplémentaire par sa nature imprévisible et aléatoire : d’une part, un modèle doit s’adapter aux données qu’il représente, d’autre part, les données sont en constante évolution. Il est alors primordial de recalibrer le modèle avant qu’il ne sous-performe. La maintenance en condition opérationnelle doit nécessairement appréhender les besoins de recalibration et de redéploiement des modèles propres au ML.
Si les frameworks de modélisation abondent, finalement peu d’entre eux proposent des outils pour déployer des modèles. Citons h2o, tensorflow et xgboost que nous envisageons dans cet article. Or, pour communiquer un modèle vers un nouvel environnement ou une autre application, il faut pouvoir le présenter à un moment ou à un autre sous une forme adéquate d’octets. Ces formats sont binaires tels hdf5 et MOJO ou textes tels PMML et json. Nous nous intéressons dans cet article aux différentes possibilités pour représenter un modèle, sujet trop souvent négligé.
Industrialisation d’un modèle
Dans le cycle de vie des modèles, la phase d’apprentissage, comme de ré-apprentissage, se fait à part dans un environnement de développement. Se pose alors le problème suivant : comment déployer un nouveau modèle mis à jour en production ? Peu importe le mécanisme de communication du modèle, par exemple via un simple fichier, une base de données ou une requête HTTP, le modèle doit être encodé en suite d’octets. On parle alors de sérialisation du modèle. Si la sérialisation semble secondaire en phase exploratoire du développement d’une application ML, celle-ci devient essentielle en production. Elle est malheureusement trop souvent négligée. Alors, quelles sont les solutions de sérialisation d’un modèle ?
État de l’art
Sérialisation d’objets
Un protocole standard de sérialisation d’objets propre au langage de programmation peut être utilisé pour sérialiser les modèles. Il s’agit par exemple de pickle en python, rds en R et l’interface sérialisable en java. Quoique d’apparence simple à court terme, il faut se rappeler que ce type de format n’est pas adapté au stockage du modèle à moyen ou long terme. En effet, le résultat est lié à l’ensemble des dépendances du modèle, incluant non seulement ses paramètres, mais aussi ses fonctionnalités, leur implémentation et les packages tiers nécessaires. Par exemple, un changement de version dans une dépendance ou une petite modification dans l’implémentation de la prédiction peuvent rendre incompatible un modèle préalablement sérialisé.
Package (R ou python)
Il est également commun d’inclure le code avec le modèle dans un package distribué dans une archive. Cette solution permet une installation standard du package en production incluant l’installation des dépendances provenant du même système de packaging, généralement propre au langage (par exemple des wheels python ou des packages R). Toutefois, il est à noter que l’environnement de production doit être configuré pour installer le package et interpréter le code. Les dépendances système liées au package doivent être, quant à elles, gérées par un autre gestionnaire de package tel que apt ou yum.
Conteneur
Le problème des dépendances du modèle peut être entièrement résolu en utilisant une technologie de conteneurisation comme Docker. Le modèle est représenté par une image contenant l’ensemble de son environnement d’exécution, ce qui peut faciliter son déploiement. Toutefois, l’image qui en résulte est souvent volumineuse. Il n’est pas rare de voir une image de l’ordre de 1Go qui, de fait, n’est pas adaptée lorsqu’il s’agit de recalibrer fréquemment des modèles. En effet, une livraison récurrente à des fréquences élevées de ce genre d’image amène des coûts de fonctionnement importants et possiblement des interruptions de service. Il est difficile d’envisager de mettre un docker de 1Go à jour toutes les heures par exemple.
Sérialisation des paramètres
Pour qu’un modèle puisse prédire, ses paramètres sont calibrés lors de l’apprentissage. Il est alors possible de ne sérialiser que ses paramètres, soit le minimum d’information pour récupérer le modèle. Implicitement, l’exécutable capable de les interpréter est pré-déployé. Si cette approche a le mérite de la plus grande simplicité et de la robustesse, elle demande une bonne planification pour ne pas être trop rigide, l’exécutable restant fixe une fois déployé. Par exemple, il faut planifier la possibilité d’ajouter ou enlever des variables.
Nous considérons que cette planification peut grandement bénéficier d’un design avec une séparation claire entre structure de données et algorithmes agissant sur cette structure (apprentissage, prédiction, sauvegarde). Nous proposons en seconde partie d’article un exemple d’implémentation pour les forêts aléatoires.
Plusieurs outils de modélisation implémentent cette stratégie, en voici quelques exemples :
- xgboost : framework polyglotte de boosting de gradient qui implémentait leur propre format binaire, mais depuis la version 1.0.0 la librairie se tourne vers le format json.
- h2o : framework en java, tous les modèles peuvent être convertis en POJO ou MOJO, les paramètres étant sauvegardés dans une archive zip.
- tensorflow : framework initialement de réseaux de neurones. Ces derniers étant souvent volumineux, une attention particulière est portée à l’efficacité de la sérialisation. Tensorflow supporte le format binaire hdf5, et plus récemment dans leur propre format checkpoint.
Modélisation déclarative
Si la sérialisation des paramètres permet de séparer la description du modèle du moteur de prédiction, elle n’est pas suffisamment flexible pour décrire les parties algorithmiques de la prédiction. Les langages déclaratifs permettent de conserver cette séparation tout en permettant cette flexibilité supplémentaire. Même si le domaine est encore jeune, il existe plusieurs efforts notables dans cette direction. Un premier vient du Data Mining Group, créateur du format PMML, qui prône désormais le format PFA, un langage descriptif en json similaire à Lisp. Evoquons également la fondation Apache et son projet haute priorité systemML. Ce dernier définit un langage descriptif similaire à R, ainsi que plusieurs modes d’exécution, par exemple un mode distribué via spark.
Si la modélisation déclarative est à ce jour sous-développée, elle est très prometteuse. En effet, elle permet en production de s’affranchir de la dépendance aux multiples frameworks desquels les modèles pourraient provenir et même de devoir déployer un exécutable par modèle. L’installation d’un seul moteur d’interprétation dans le language descriptif choisi est suffisant pour pouvoir déployer par la suite n’importe quel modèle de Machine Learning. À la différence d’un language généraliste scripté comme python ou R, un language descriptif est beaucoup plus robuste car moins permissif : on ne peut manipuler les fichiers du système dans un tel language par exemple.
Comment choisir ?
Chaque solution propose son équilibre entre robustesse et flexibilité, simplicité et expressivité. La solution la plus adaptée dépend toujours du projet, de son contexte et de l’infrastructure ciblée.
Code versus configurations
Un modèle ML doit pouvoir produire des prédictions. Pour ce faire, l’ensemble des paramètres du modèle nécessaires pour prédire sont calibrés lors de l’apprentissage. Lorsque le modèle est recalibré, nous avons le choix entre livrer un exécutable ou livrer des paramètres pour reconfigurer un exécutable existant. C’est le dilemme classique entre code et configurations, le code étant plus flexible et moins sûr que les configurations. En réalité, ce sont les deux extrêmes d’un spectre de solutions.
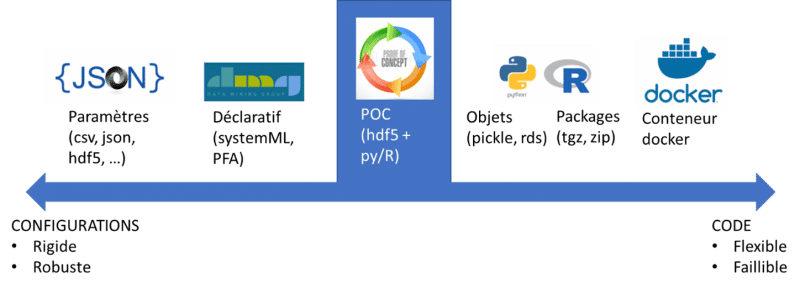
Figure 1 : code versus configurations
Préconisations
- Data Scientist : s’il n’est pas nécessaire d’optimiser la rapidité d’exécution des prédictions du modèle, utiliser des modèles implémentés dans un format déclaratif tels que systemML, PFA ou PMML. Ces derniers offrent le meilleur rapport expressivité/robustesse. Si toutefois l’efficacité est un enjeu fort, privilégier plutôt des modèles implémentant une sérialisation robuste dans un format binaire tel que hdf5.
- Architecte : utiliser un dépôt de binaire pour stocker et gérer les modèles et exiger de déployer les applications de Machine Learning via un containeur tel que Docker. Ce dernier doit pouvoir récupérer le modèle du dépôt. Docker permet aux développeurs de conserver un niveau de flexibilité appréciable tout en unifiant la gestion des diverses applications pour les opérateurs. Aujourd’hui, Docker est également prédominant dans le cloud, permettant ainsi de passer à l’échelle plus facilement si nécessaire.
Exemple de mise en œuvre d’un algorithme de type random forest
Nous aimerions à la fois avoir la main sur les fonctions de prédictions déployées et un système robuste en production. Nous allons donc chercher à alléger R ou python de leurs dépendances fonctionnelles en gardant la main sur la flexibilité offerte par ces langages. Nous allons donc garder les paramètres minimaux nécessaires à une prévision et des fonctions uniquement dédiées à la prédiction.
Nous avons voulu simplifier au maximum les informations à livrer après la calibration d’une forêt aléatoire de classification. Pour notre exercice, nous avons besoin d’un modèle simple. Nous construirons :
- Un fichier de paramètres nécessaire à la prévision
- Une fonction pour lire ce fichier
- Une fonction pour prévoir un nouvel individu
Pour livrer un modèle, il suffira simplement de joindre le fichier de paramètres et les deux fonctions nécessaires à la prévision et de l’envoyer au MLops. Les éléments nécessaires à la prévision ont été structurés de la façon suivante :

Figure 2 : livraison du modèle en utilisant le format json
Cette structure simple et très légère permet de garder les arbres séparés des autres paramètres.
Format hdf5
Nous avons retenu un format hiérarchique binaire, en l’occurrence hdf5. C’est en effet un format utilisé par tensorflow pour stocker et calibrer les réseaux de neurones. Il est rapide, très efficace pour les nombres et adapté à notre schéma de données en groupes / sous-groupes. C’est un format peu corruptible et facile à transporter (un seul fichier). De plus, la compression déjà implémentée.
Concrètement, avec R
La fonction de sérialisation d’un modèle de type random forest en hdf5 peut s’exprimer de la façon suivante :

Figure 3 : fonction de sérialisation d’un modèle de type random forest en hdf5
Exemple de code pour un service de prévision robuste, facilement auditable et monitorable (la seule dépendance nécessaire est la librairie rhdf5) :


Figure 4 : exemple de code sous R
Conclusion
La mise en production de modèles est aujourd’hui l’un des sujets importants dans l’univers de la data science. De nombreuses solutions existent, présentant toutes des avantages et des contraintes. Des solutions les plus rigides et stables avec la livraison d’un fichier aux solutions les plus intégrées avec docker, chacune peut être adaptée ou non suivant les cas d’utilisation. Avec les solutions intermédiaires comme PMML et PFA, nous avons un bon compromis entre stabilité et souplesse. Notre proposition, avec l’exemple de la random forest, est une solution à la fois souple et robuste. En effet, la très faible dépendance fonctionnelle, couplée à la facilité d’implémentation, que ce soit en R ou en python, nous conforte dans nos choix. L’une des extensions possibles sera d’étendre ces fonctions à d’autres types de modèles (régressions, xgboost). De plus, le choix de hdf5 comme format de sérialisation nous offre une solution multi-langage, rapide et mature. Il est en adéquation parfaite avec les besoins d’un MLops.


