Dans le cadre de ses travaux de R&D, Datastorm a confié une mission exploratoire sur le Speech-to-Text à Kaicheng LI, étudiant en Data Science et Génie statistique à l’ENSAI. Pour le jeune ingénieur, l’expérience aura été formatrice sur tous les plans. Interview.
 Kaicheng, peux-tu nous détailler les différentes phases de ton stage sur le Speech-to-Text chez Datastorm ?
Kaicheng, peux-tu nous détailler les différentes phases de ton stage sur le Speech-to-Text chez Datastorm ?
Kaicheng LI : Je me suis d’abord documenté pour comprendre comment fonctionne la reconnaissance vocale, et j’ai appris comment utiliser les services de reconnaissance vocale de type API fournis par les grandes entreprises du marché, telles que Google et Baidu. Afin de comprendre en profondeur le sujet, j’ai étudié une extraction basique des caractéristiques vocales : FBank, puis une meilleure extraction des caractéristiques vocales : MFCC, après laquelle j’ai commencé à étudier les modèles associés : modèle HMM-GMM, puis HMM-RNN, HMM-LSTM, etc. Après cette approche théorique, j’ai commencé à explorer plusieurs frameworks pour entraîner des modèles de reconnaissance vocale.
Et quel framework as-tu retenu ?
K.L. : En comparant plusieurs d’entre eux, j’ai trouvé que Kaldi était le plus complet et le plus polyvalent, tandis que Speechbrain était le plus puissant et le plus facile à utiliser. J’ai donc commencé à expérimenter avec Kaldi, sur Linux, pour l’entraînement du modèle et j’ai finalement réussi à entraîner mon propre modèle de reconnaissance vocale en utilisant une base de données open-source. J’ai consacré la dernière période de mon stage au développement d’une application web en R Shiny.
Tu nous présentes l’application ?
K.L. : Bien sûr. Les fonctionnalités de l’application sont les suivantes :
1. Reconnaissance vocale en anglais et en français
2. Reconnaissance vocale par l’API de Google (en ligne) et reconnaissance vocale par modèle Huggingface (hors ligne)
3. Reconnaissance vocale d’un fichier audio enregistré via le microphone
4. Lecture d’un fichier audio
5. Ajout de la ponctuation du texte
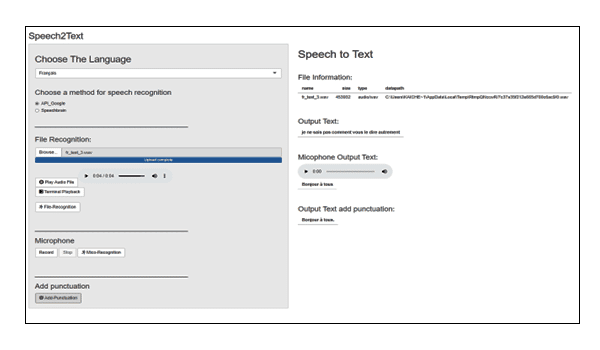
L’interface est simple, avec une console à gauche pour la sélection de la langue et les options de reconnaissance vocale. Elle est compatible avec la saisie de fichiers et la saisie par microphone, et offre la possibilité d’ajouter de la ponctuation au texte.
A droite, c’est l’écran de sortie, qui affiche les informations de base sur le fichier vocal et montre les résultats de la reconnaissance vocale du fichier et de la reconnaissance vocale du microphone séparément. En bas de l’écran, le texte est affiché après l’ajout de la ponctuation.
C’est une vraie chance de pouvoir effectuer un stage de fin d’études Recherche & Développement dans un environnement porteur.
Que t’a apporté ce stage chez Datastorm ?
K.L. : Au niveau théorique, je me suis formé aux principes de la reconnaissance vocale, un champ encore assez nouveau en data science et très exploratoire. C’est une vraie chance de pouvoir effectuer un stage de fin d’études Recherche & Développement dans un environnement porteur comme celui qu’offre Datastorm. Au niveau technique, j’ai appris à utiliser Linux, à entraîner des modèles en utilisant Kaldi, à appliquer les modèles NLP de Huggingface, à créer des packages Python et à créer une application front-end en utilisant R Shiny.
Un stage très complet en fait ?
K.L. : En effet. Mon stage m’a non seulement donné un aperçu des activités quotidiennes d’un cabinet d’expertise en data science, mais m’a également enseigné de nombreuses compétences dont j’aurai besoin dans mon futur emploi. Et puis il y a une atmosphère très accueillante chez Datastorm, j’ai vraiment apprécié cette ambiance et je remercie toute l’équipe, en particulier Martin Masson et Thibaut Dubois qui m’ont épaulé et accompagné pendant toute ma mission.


